Neural networks help discover how languages are related
How are the languages of the world related? This is the central question in the discipline of historical linguistics. In his MSc thesis, Peter Dekker studied how neural networks can help to reconstruct the ancestry of languages.
Historical linguistics is concerned with reconstructing the history and relatedness between languages of the world. Recently, this discipline gained new insights by applying computational methods, such as new proposals for the birthplace of the Indo-European language family, to which most European languages belong (Bouckaert et al., 2012). As I am passionate about both historical linguistics and machine learning, I decided to combine these two fields in my master’s thesis at the CLC lab in 2018.
Predicting words between languages
Can you guess the Italian word for stone (pietra), if I give you the Spanish word (piedra)? What about if I give you the German word (Stein)? This one seems harder, right? The reason why the second task is harder is because Italian is more closely related to Spanish than to German. The hypothesis of my thesis was that the ability of a machine learning model to predict a word in one language from the corresponding word in another language is a measure for how closely these languages are related. Based on this idea, I developed an approach to word prediction: I trained a machine learning model on pairs of words in two languages, and the model learned which sounds in an input language correspond to which sounds in the target language. Then, I let the model predict new words in the target language from words in the input language. The regularity of sound change is a central thesis in historical linguistics: if a sound changes into another sound in one word, between two languages, the sound should also change into the other sound in all other words. Machine learning models rely on similar concepts, since they learn regularities in training examples.
Illustration by Philipp Wicke
A neural network model for word prediction
I used the NorthEuraLex dataset (Dellert & Jäger, 2017), developed at the University of Tübingen. It consists of phonetic representations of 1000 words in 100 languages spoken across Northern Eurasia. I selected all pairs of Germanic and Slavic languages. Next, I trained two neural network models to perform word prediction on this data: a recurrent neural network (RNN) encoder-decoder and a structured perceptron. The simpler structured perceptron tended to give a better performance, whereas the encoder-decoder provides more flexibility to be extended.
Below is an example of a prediction result, for the prediction from Dutch to German. The model is fed a Dutch word and predicts the corresponding German word. The distance between the predicted and the target German word indicates how accurate the prediction was.
| Input | Target | Prediction | Distance |
|---|---|---|---|
| blut | blut | blut | 0.00 |
| inslap3 | ainSlaf3n | inSlaun | 0.33 |
| blot | blat | blat | 0.00 |
| wExan | vEge3n | vag3n | 0.33 |
| xlot | glat | glat | 0.00 |
| warhEit | vaahait | vaahait | 0.00 |
| orbEit | aabait | oabait | 0.17 |
| mElk3 | mElk3n | mEl3n | 0.17 |
| vostbind3 | anbind3n | fostaiN3n | 0.78 |
| hak | hak3n | hak | 0.40 |
I computed the overall distance between every pair of languages by averaging distance scores over all 1000 word predictions. Then, I created an ancestry tree for each language family by hierarchically clustering, based on the distances between language pairs. This is how it looks for the Slavic language family, when using the structured perceptron:
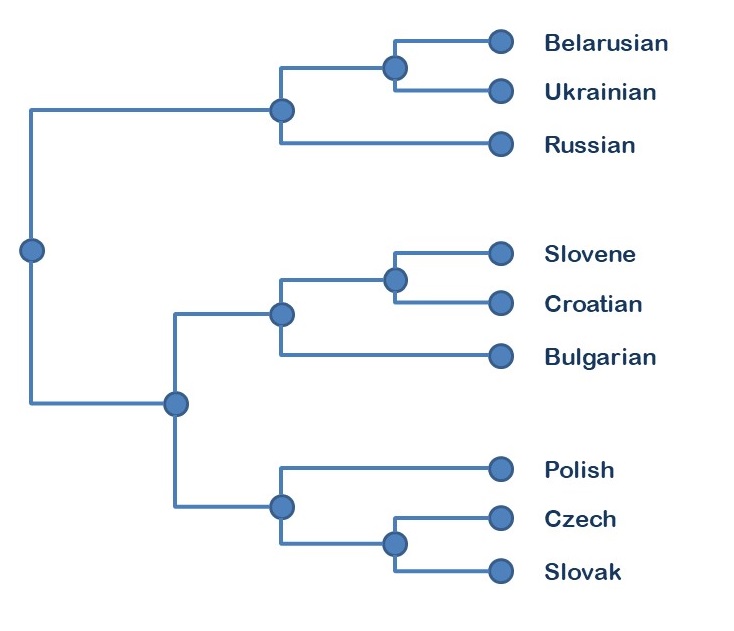
A reconstructed ancestry tree for Slavic languages
This tree exactly matches the Glottolog ancestry tree for this family (Hammarström, Forkel, & Haspelmath, 2017). This is a nice proof of concept: word prediction is able to replicate existing knowledge in historical linguistics.
Outlook
Whereas most research at the CLC lab investigates the cognitive basis of language, I use neural networks to investigate the ancestry of languages. These are two different research objectives - but they can be combined in a fascinating way. When looking at language change, one can investigate which patterns are common across multiple language families. These changes may be caused by a common cognitive mechanism.
With my thesis, I hope to show the value of deep learning for historical linguistics. Word prediction can validate existing ancestry trees and may support the creation of new insights in historical linguistics.
A full version of my thesis can be found here. The thesis was supervised by Jelle Zuidema from the CLC lab and Gerhard Jäger from the University of Tübingen.
References
Dellert, J., & Jäger, G. (2017). NorthEuraLex.
Hammarström, H., Forkel, R., & Haspelmath, M. (2017). Glottolog 3.1. Max Planck Institute for the Science of Human History.
Bouckaert, R., Lemey, P., Dunn, M., Greenhill, S. J., Alekseyenko, A. V., Drummond, A. J., … Atkinson, Q. D. (2012). Mapping the Origins and Expansion of the Indo-European Language Family. Science, 337, 957–960. DOI